Künstliche Intelligenz ist schon lange im Alltag eingekehrt. Streaming-Plattformen wie Netflix, YouTube oder Amazon Prime geben uns Vorschläge für die nächsten Filme, das Smartphone erkennt recht souverän Gesichter und vertraut der Gesichtserkennung die Displaysperre an. In der Landwirtschaft können Maschinen Felder zum Teil selbst bewirtschaften und in der Industrie nimmt die Automatisierung der Produktion immer stärker zu. Das sind nur wenige von vielen Beispielen, wie Künstliche Intelligenz unsere Welt verändert. Über den Begriff der KI selbst und dessen Definition lassen sich Bücher über Bücher verfassen und man käme wohl auf keinen gemeinsamen Nenner. Wir wollen uns Übersetzungstools etwas genauer anschauen. Programme wie Google Translate und DeepL sollen menschliche Übersetzer obsolet machen. Doch wie gut funktionieren diese Programme und woran scheitern sie?
Was soll ein Übersetzungsprogramm eigentlich können?
Natürlich übersetzen. Aber was soll das heißen? Im einfachsten Fall nimmt sich ein Übersetzer Wort für Wort vor und ersetzt sie mit Vokabeln in der gewünschten Sprache. Dass dabei häufig Unsinn herauskäme, ist wohl offensichtlich. ”Ich glaube ich spinne” mit ”I think I spider” zu übersetzen, ist eines der bekanntesten Beispiele, wie man nicht an Übersetzungen herangehen sollte. Ein guter Übersetzer muss Texte also verstehen, um sie sinnvoll in einer anderen Sprache zu formulieren. Künstliche Intelligenz hat hier beeindruckende Fortschritte gemacht, wie man etwa auch an den immer „menschenähnlicheren“ Chatbots sieht. Trotzdem kommen Maschinen beim Verstehen von Sprache und Texten bis heute nicht an den Menschen heran.
Was den menschlichen vom künstlichen Übersetzer unterscheidet
Im Verstehen liegt also im Besonderen der Unterschied zwischen künstlicher und menschlicher Intelligenz. Eine Maschine verwendet Übersetzungsalgorithmen, die normalerweise mit Statistiken arbeiten. Der Algorithmus schaut sich eine Wortfolge an und übersetzt sie nach der ihr vorliegenden Statistik in die möglichst übereinstimmende Wortfolge der gewünschten Sprache. Dabei bedient sich die künstliche Intelligenz aus einem möglichst großen Pool von Textdateien, in denen solche Wortfolgen vorkommen und bewertet sie nach bestimmt Vorgaben. Die modernsten Ansätze kombinieren diese statistische Methode mit künstlichen neuronalen Netzen und maschinellem Lernen, wodurch die KI beginnt, auch komplexere Sprachmuster zu erkennen.
Daraus ergeben sich Übersetzungen, die das Programm als mehr oder weniger sinnvoll bewertet und am Ende spuckt es die vermeintlich beste Übersetzung aus. Die KI kann dabei auf einen nahezu unbegrenzten Wortschatz zurückgreifen und ist dem Menschen in der Hinsicht weit überlegen. Doch das ist nur ein Teil dessen, was Sprache ausmacht.
Was maschinellen Übersetzern fehlt
Sprachwissenschaftler unterscheiden zwischen dem reinen Wortwissen und dem sogenannten enzyklopädischen Wissen. An Letzterem scheitert Künstliche Intelligenz besonders, weshalb maschinelle Übersetzungen bei vielen Themenbereichen nicht so gut sind, wie ein professionelles Übersetzungsbüro sie formulieren würde. Gemeint mit enzyklopädischem Wissen ist, was der Mensch über die Welt weiß und wie er es sprachlich kommuniziert. Das bereitet der KI besonders bei Wortbildern und unausgesprochenen Sinnzusammenhängen große Probleme.
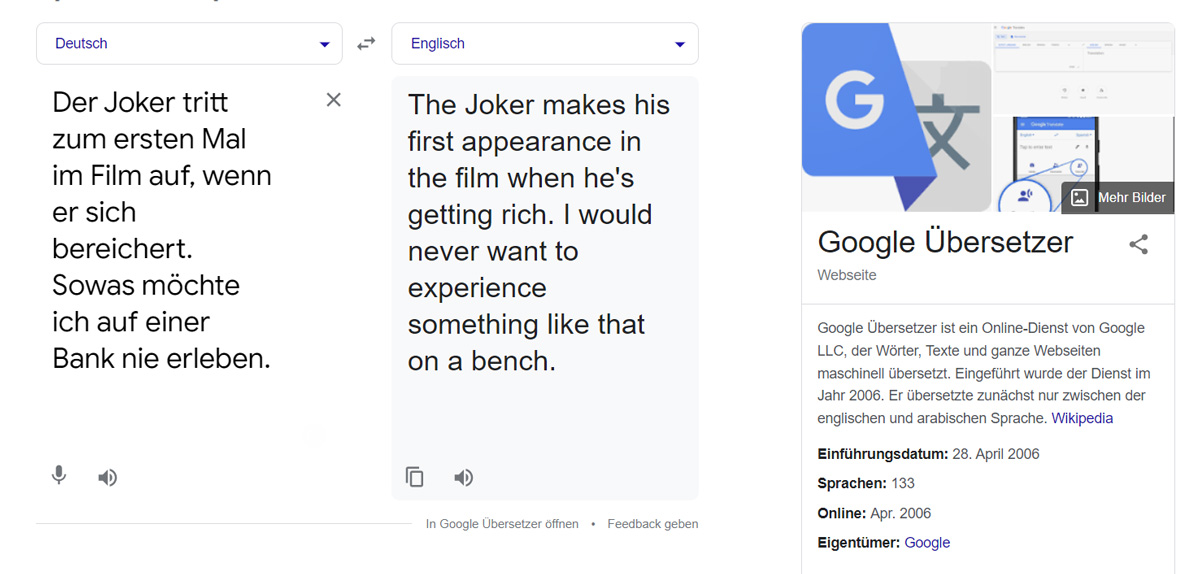
Anspielungen auf ”gemeinschaftliche” Ereignisse oder themenspezifisches Wissen und daraus kontextbezogene Formulierungen, die der menschliche Verstand sofort versteht, sind für Übersetzungsprogramme ein Graus. Wenn jemand über den Banküberfall vom Joker in The Dark Knight etwas schreibt wie: „Der Joker tritt zum ersten Mal im Film auf, wenn er sich bereichert” und daraufhin, dass der Autor auf einer Bank so etwas nie erleben möchte, dann ist jedem klar, dass nicht die Sitzbank gemeint ist. Nur Google Translate offenbar nicht: