Lange waren die Chinesen nur für Markenpiraterie bekannt. Dass sie auch anders können, sollte sich nun langsam herumgesprochen haben. Dass sie auch ernsthafte Forschung betreiben können, sollte inzwischen auch in der öffentlichen Wahrnehmung angekommen sein. Nun haben Forscher der Zhejiang University, eine der führenden Forschungsuniversitäten Chinas, nachgewiesen, dass sprachgestützte Assistenten mit “DolphinAttack”kompromittierbar sind.
Am Anfang einer jeden Forschung steht eine Theorie, die nachgewiesen werden soll. Die Theorie der Forscher war hier, dass sprachgestützte Systeme, bzw. Spracherkennungssysteme unhörbar manipulierbar sind. Um diese Theorie zu belegen oder zu widerlegen, haben die Forscher verschiedene Fragen gestellt, die sich dazu eignen, diese Theorie zu bestätigen oder zu widerlegen. Diese Fragen waren:
Unhörbare Sprachbefehle erscheinen eigentlich undurchführbar, denn es ergeben sich dabei einige Schwierigkeiten, was zu weiteren Fragen führte:
Mithilfe der Lösungen der Fragen muss dann durch hinreichende Tests nachgewiesen werden, dass die Theorie in sich schlüssig und plausibel ist und auch etwaige auftretende Schwierigkeiten erfolgreich beseitigt werden können.
Trotzdem bleibt eine Theorie in der Wissenschaft immer eine Theorie, solange sie nicht widerlegt wird oder bewiesen werden kann. Im vorliegenden Fall konnte die Theorie für die verwendeten Systeme bewiesen werden.
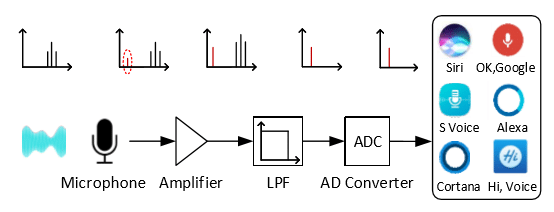
Die Forscher haben es also geschafft, diese oben angesprochenen Probleme zu umschiffen. Üblicherweise nimmt ein Mikrofon die Töne auf, ein Verstärker (Amplifier) verstärkt sie, dann laufen sie durch einen Filter, der die hohen Frequenzen herausfiltert bzw. die tiefen durchlässt (Low Frequency Pass Filter, im obigen Bild “Filter”, im folgenden Bild “LPF”) und sie dann an den Analog-Digital-Wandler (AD Converter) schickt.
Das erste technische Problem bestand nun darin, zu verhindern, dass die Ultraschallfrequenzen mit dem Sprachbefehl vom Filter herausgefiltert werden. Dabei haben sich nun die Forscher einen technischen Effekt des Mikrofons zunutze gemacht. Meistens nimmt man an, dass ein Mikrofon die Töne aufnimmt und absolut linear in den Verstärker weiter gibt. Das ist aber nicht der Fall. Tatsächlich arbeiten die Mikrofone nicht linear, was bedeutet, dass sie zusätzliche Ober- und Unterschwingungen und andere Kreuzprodukte erzeugen. Im oberen Bild ist diese neue Unterschwingung rot umkringelt. Nachdem nun die Ultraschallfrequenzen herausgefiltert werden, bleiben die (vom Mikrofon neu erzeugten!) Frequenzen im hörbaren Bereich zurück, welche dann einwandfrei interpretiert werden konnten.
Sie nahmen also die gesprochenen Kommandos auf, erhöhten bzw. verschoben die Frequenz in den unhörbaren Bereich. Dann modulierten sie die Signale so auf die Trägerfrequenz, dass die Nicht-Linearität der Mikrofone ausgenutzt wurde. Zum Schluss spielten sie sie mit einem normalen Lautsprecher wieder ab.
Manche Sprachassistenten lassen sich auf die eigene Stimme trainieren. In diesem Fall wäre es notwendig, den Sprecher einige Zeit aufzuzeichnen, um aus dem, was er sagt, den gewünschten Befehl neu zu synthetisieren. Zum Beispiel lässt sich aus dem Satz “He carries cake in the Ctity” der Befehl “Hey Siri” synthetisieren (He+cake = Hey, City+carries = Siri). Allerdings hat man ja nun nicht immer bzw. in den vorliegenden Versuchsbedingungen gar nicht die Möglichkeit, die Stimme des Betroffenen aufzuzeichnen. Trotzdem ist es aber so, dass sich viele Stimmen ähnlich genug sind, dass z.B. ein Bekannter das eigene Smartphone aktivieren kann. Deshalb nutzten sie Brute-Force-Methoden, um die betreffende Stimme nachzuahmen. Mithilfe von verschiedenen Text-To-Speech-Systemen (Text-zu-Sprache, TTS) konnten sie etwa 90 verschiedene TTS-Stimmen erhalten, mit denen die meisten Stimmen nachgeahmt werden können, also die meisten Smartphones aktivierbar sind.
War die Stimmerkennung mit dem Stimmaktivierungsbefehl (“Hey Siri”) erst einmal geknackt, konnte dann mit irgendeiner Stimme der gewünschte Befehl eingegeben werden, denn die weiteren Befehle werden nicht mehr durch die Stimmerkennung überprüft. Dazu haben sie Googles Sprachausgabe genutzt.
Nicht alle Smartphones oder Lautsprechersysteme (z.B. Alexa) nutzen die gleichen Komponenten, die verwendeten Mikrofone weisen leicht unterschiedliches Verhalten auf. Dazu haben sie verschiedene Tests durchgeführt, um die Frequenzen herauszufinden, die das beste Ergebnis lieferten. Ziel war es im vorliegenden Fall, mit einem Samsung Galaxy S6 Edge ein iPhone zu knacken. Deshalb testeten sie die Frequenzen, mit denen das Samsung die besten Ergebnisse (Sprache aufnehmen, synthetisieren und modulieren, abspielen) hatte und nutzten diese.
Im folgenden Film kann man sehen, wie das gesperrte iPhone aktiviert und ein Telefonanruf gestartet wird.
Auf diese Art haben sie es geschafft, folgende Gefährdungspotenziale auszunutzen:
Das komplette System aus Handy (Samsung Galaxy S6 Edge), einem Ultraschallwandler, einem Verstärker und einer externen Batterie passt in eine Hosentasche und kostet (ohne das Smartphone) rund $ 3:
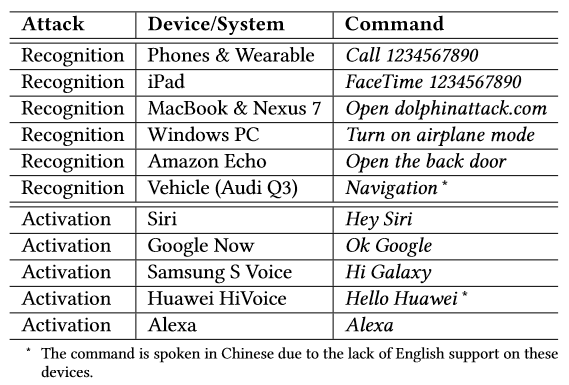
Die forscher nannten ihren Mechanismus, ihr Gerät, DolphinAttack und manipulierten damit Siri, GoogleNow, SamsungSVoice, HuaweiHiVoice, Cortana, Alexa und das Auto-System von einem Audi Q3. Jedes dieser Systeme war mindestens über eines, meistens aber mehrere der oben genannten Gefährdungspotenziale angreifbar.
Die getesteten Geräte waren:
Apple (iPhone 4s, 5s, SE, SE (mit anderem OS), 6s, 6 Plus, 7 Plus, watch, iPad mini 4, MacBook), LG Nexus 5X, Asus Nexus 7, Samsung Galaxy S6 Edge, Huawei Honor 7, Lenovo ThinkPad T440pm, Amazon Echo und Audi Q3
mit folgenden Betriebssystemen:
Apple iOS 9.3.5, 10.0.2, 10.2.1, 10.3.1, 10.3.2, watchOS 3.1, macOS Sierra, Android 6.0, 6.0.1, 7.1.1, Windows 10
Die Forscher waren natürlich auch fleißig und haben auch noch verschiedene andere Faktoren untersucht. So stellten sie fest, dass der Erfolg des Angriffs auch von der Entfernung abhing (< 80 cm ist am besten), der Lautstärke (125 dB), der Lautstärke der Hintergrundgeräusche (< 55 dB ist am besten), der verwendeten Sprachen (Chinesisch, Englisch, Spanisch, Französisch, Deutsch (abhängig vom verwendeten Sprachbefehl, meistens 100%, bei wenigen Ausnahmen nur 90%).
Wenn man mal die Tatsache, dass der eigene intelligente Lautsprecher, der Laptop oder das Tablet, das Smartphone oder gar das Auto vor der Tür betroffen sind, etwas sacken lässt, dann stellt man sehr viele Möglichkeiten fest, in denen eine solche Sicherheitslücke durchaus interessante Folgerungen eröffnet: So könnte man, wenn man in der Stadt unterwegs ist, nicht nur analog der offenen WLANs auch durch aufgestellte Werbeschilder mit versteckten Lautsprechern auf die beworbenen Webseiten gelotst werden. Abends vor dem Fernseher könnte die Werbung ebenfalls die betreffende Webseite öffnen. Bei Navigationssystemen wäre es auch denkbar, dass man statt zuhause auf dem Parkplatz des nächsten Schnellimbisses landet. Kriminellen wäre ebenfalls Tür und Tor geöffnet, Bestellungen aufzugeben, Telefonanrufe zu tätigen, oder kostenpflichtige SMS abzusetzen. Mal vom simplen Abhören und Datenklau bzw. der Installation von Trojanern oder RootKits ganz abgesehen.
Extrem paranoide wäre folgendes Szenario: Die Verbreitung entsprechender Befehle über die Medien (also z.B. Radio, Fernsehen, aber auch Internet-Videos/Musik) in Werbung z.B., mit dem Ziel, hunderte, tausende Geräte so zu manipulieren, dass Daten, Geld etc. abgreifbar wären…
Als erstes haben sich die chinesischen Forscher Gedanken zu den hardware-seitigen Verbesserungsmöglichkeiten gemacht. Allen voran sind hier die Mikrofone zu nennen, die auch Geräusche mit höheren Frequenzen als 20 kHz aufnehmen können, obwohl diese gar nicht mehr hörbar und damit nicht notwendig sind. Zum Beispiel konnte das verwendete iPhone 6 Plus diese Frequenzen nicht aufnehmen (Anmerkung von mir: Fraglich, ob es ein Einzelfall war). Außerdem gibt es noch die Möglichkeit, ein zusätzliches Modul vor dem LPF (Filter für die niedrigen Frequenzen) zu installieren, das solche versteckten Sprachbefehle erkennt (Mathematik und Fourier lassen grüßen, weitere Infos dazu im Papier der Forscher, Link unten).
Als nächstes haben sie sich die Software vorgenommen. Hier ist es tatsächlich so, dass Software darauf trainiert werden kann, zuverlässig die gefälschten Sprachkommandos zu erkennen. Alle angefragten Hersteller (Google und Apple) versicherten wenig überraschend, dass ihnen die Sicherheit ihrer Kunden sehr am Herzen läge. Wir werden sehen, welcher Hersteller hier am schnellsten nachrüstet. MSPowerUser hat auch bei Microsoft nachgefragt, aber bis dato fehlt noch die Antwort.
Bis dahin haben die Verbraucher nur die Möglichkeit, die automatische Spracherkennung ihrer Geräte auszuschalten, damit die Geräte nicht mehr durch ein Schlüsselwort (“Hey, Siri”) aufwachen können.
Was macht Ihr nun? Werdet Ihr deswegen die Sprachsteuerung vom Handy oder Alexa/Echo oder vom Auto ausschalten?
Quellen:
Originales Papier der Forscher: https://www.hackread.com/wp-content/uploads/2017/09/dolphinattack-siri-and-alexa-can-be-hacked.pdf
MSPowerUser: https://mspoweruser.com/hackers-can-take-control-cortana-voice-commands-wouldnt-hear-coming/
Der Microsoft Flight Simulator wird optisch weiter aufgewertet. Wir wissen, dass es auch unter unseren…
Die meisten unserer Leser dürften zu Hause über einen Schreibtisch verfügen, an welchem nicht nur…
Manche Dinge brauchen ihre Zeit. Als die Apple Vision Pro angekündigt wurde und letztlich an…
Zum Thema Nachhaltigkeit gehört auch der Umstand, elektrische Geräte zu reparieren und nach diesem erfolgreichen…
Microsoft-Dienste und E-Mail-Server sind in den letzten Wochen nicht immer positiv in den Medien hervorgehoben…
Ein smarter WLAN- und Bluetooth-Lautsprecher inkl. Alexa und einem gigantischen sowie sattem Klang – so…
Diese Webseite benutzt Cookies.
{kind=link}
{kind=link}
{kind=link}
{kind=link}
Zeige Kommentare
Wow! Ich hab gerade das Mikro abgeklebt! ☹
Okay Nice
Einen sog. 20Khz-Filter gibt es nicht.. Der technisch korrekte Ausdruck wäre "Tiefpassfilter" (alles was
unterhalb einer bestimmten Frequenz liegt, darf passieren, alles oberhalb wird geblockt).Ein analoger
Tiefpassfilter Ist aber unsinnig.
Denn da Smartphones, genauso wie Computer nicht analog, sondern digital arbeiten
kommt hinter jedem Mikrofon ein A/D-Wandler (Analog/Digital-Wandler)...und der
ist i.d.R. programmierbar....d.h. ein Patch genügt. um diese "superriesige Riesenbedrohung"
durch diese realitätfremde Laborexperiment zu beseitigen.
Aber in der Wirklichkeit dürfte nicht einmal das notwendig sein, weil alleine schon die ganz
normalen Umgebungsgeräusche diesen"supergefährlichen Ultraschall-Angriff" zunichte
machen. Von anderen Faktoren ganz zu schweigen.
Die genaue technische umsetzung des Filters ist hier doch gar nicht relevant.
Und ob das tatsächlich mit einem einfachen Softwarepatch zu beheben ist, wird sich zeigen müssen. Der Filter alleine wird sowieso nichts bringen, denn laut Artikel ergeben sich im Mikro ober und unterwellen, in anderen Frequenzen und genau die gehen dann doch durch die Filter durch.
Ich gehe davon aus, dass das mit dem ADC nichts zu tun hat => Der ADC wird vermutlich nicht die Frequenzen darstellen sondern die FFT der ADC-Eingangswerte?!
Das entzieht sich meiner Kenntnis. Zumindest im zweiten Bild ist die FFT in der oberen Reihe dargestellt. Da sieht man ganz deutlich die neuen, vom Mikrofon erzeugten Frequenzen (die die Befehle übermitteln), während die oberen (>20kHz) dann im Filter wegfallen. Wann jetzt genau das Signal als FFT weitergereicht wird, weiß ich nicht, sinnvoll wäre es auch schon vor dem Filter, möglich ist es aber auch, dass die FFT erst nach dem ADC stattfindet. Spätestens vor der Spracherkennungssoftware muss das Signal dann aber als FFT vorliegen.
Die Forscher benutzen hier in der Darstellung auch eine andere Reihenfolge, als sie z.B. die Wikipedia beschreibt. Letztere beschreibt Digitalisieren, Filtern, FFT, danach die Spracherkennung.
Die Forscher haben allerdings Filtern, Digitalisierung, Spracherkennung – die FFT wird in der Darstellung ausgelassen.
Ich vermute aber, dass beides möglich ist. Am Ergebnis spielt es keine Rolle, ob die hohen Frequenzen elektronisch oder digital herausgefiltert werden. Filtere ich digital, bietet sich die vorherige FFT an.
Ich nehm wohl besser ein doppeltes Klebeband!
Ich hab für solche Fälle immer eine Fledermaus in der Tasche. Sie fängt sofort an wild zu schreien und zu flattern, wenn ein Ultraschallangriff droht.😄 🦇
Coole Idee, kaufe mir morgen stick direkt eine in Hosentaschengröße 😎
Hab die Sprachsteuerung sowieso aus. Weil ich das a bissl gruselig finde 😄
Ist der Bereich zwischen 20 kHz und 44 kHz nicht für Spiritisten und deren Runden reserviert?
Ne, die nutzen Infraschall!!! 😜